I would to show you one method very powerful, easy to implement and extremely general, because it is not related to the nature of the problem.
The method is known as coefficients of constraint (Coombs, Dawes and Tversky 1970) or uncertainty coefficient (Press & Flannery 1988) and it is based on the Mutual Information concept.Mutual Information
As you know, the Mutual Information between two random variables X and Y I(X,Y) measures the uncertainty of X knowing Y, and it says how much the uncertainty (entropy) of X is reduced by Y.
This is more clear looking at the below formula:
I(X,Y)= H(X)-H(X|Y)
Where H is the Entropy functional.
As usual, I don't want enter in theoretical discussions, but I heartily recommend a deep read of the book Elements of Information Theory: In my opinion it's the best book in that field.
Let's now rethink the mutual information as a measure of "how much helpful is the feature X to classify documents having label L":
I(L,X) = H(L)-H(L|X)
So, for each label and each features we can calculate the features ranking!
Of course you can consider the average of I(L_i,X) for each label L_i, or also more complex function over that. BTW you have to assign higher rank to the feature Xj that maximize all I(L_i,Xj).
Uncertainty coefficient
Consider a set of people's data labelled with two different labels, let's say blue and red, and let's assume that for this people we have a bunch of variables to describe them.
Moreover, let's assume that one of the variables is the social security number (SSN) or whatever univocal ID for each person.
Let me do some considerations:
- If I use the SSN to discriminate the people belonging to the red set from the people belonging to blue set, I can achieve 100% of accuracy because the classifier will not find any overlapping between different people.
- Using the SSN as predictor in a new data set never seen before by the classifier, the results will be catastrophic!
- The entropy of such variable is extremely high, because it is almost a uniform distributed variable!
To consider this fact in the "mutual information ranking", we can divide it by the entropy of the feature.
So features as SSN will receive lower rank even if it has an high I value.
This normalization is called uncertainty coefficient.
Comparative Experiment
Do you have enough about the Theory? I know that ... I did all my best to simplify it (maybe to much...).
I did some tests on the same data set used in this paper by Berkley University:
In this test the authors did a boolean experiment over REUTERS data set (actually it is very easy test) and they compared the accuracy obtained using all the words in the data set as features and the features extracted through a Latent Dirichlet Allocation method.
The data set contains 8000 docs and 15818 words. In the paper they claimed that they reduced the feature space by 99.6% and they used the entire data set to "extract" the features.
Under this condition they tested using no more than 20% of the data set as training set.
In the comparative test I focused on the second experiment mentioned: GRAIN vs NOT GRAIN.
Here you are the process I followed:
- I choose as training set 20% of the docs.
- from the above training set I extracted (after stemming and filtering process) all the words and I used them to build the boolean vectors.
- I ranked the words through the uncertainty coefficient.
- I extracted the first 60 features: that is only 0.38% of the original feature space
- I trained an SVM with a gaussian kernel and very high value of C
- I tested over the remaining 80% of the data set.
 |
| Entropy of the first 3000 features. |
As you can notice, the features having low score have low entropy: it happens because these features are present in really few documents so the distribution follows a Bernulli's distribution having "p" almost equal to 0: basically the uncertainty of the variable is very small.
Here you are the final ranking of the first 2500 features.
 |
| Uncertainty coefficient for all features. |
Results
The overall accuracy measured over the test set is equal to 96.89% and it has been depicted in the below graph (I used their original graph [figure 10.b] as base) as a red circle:
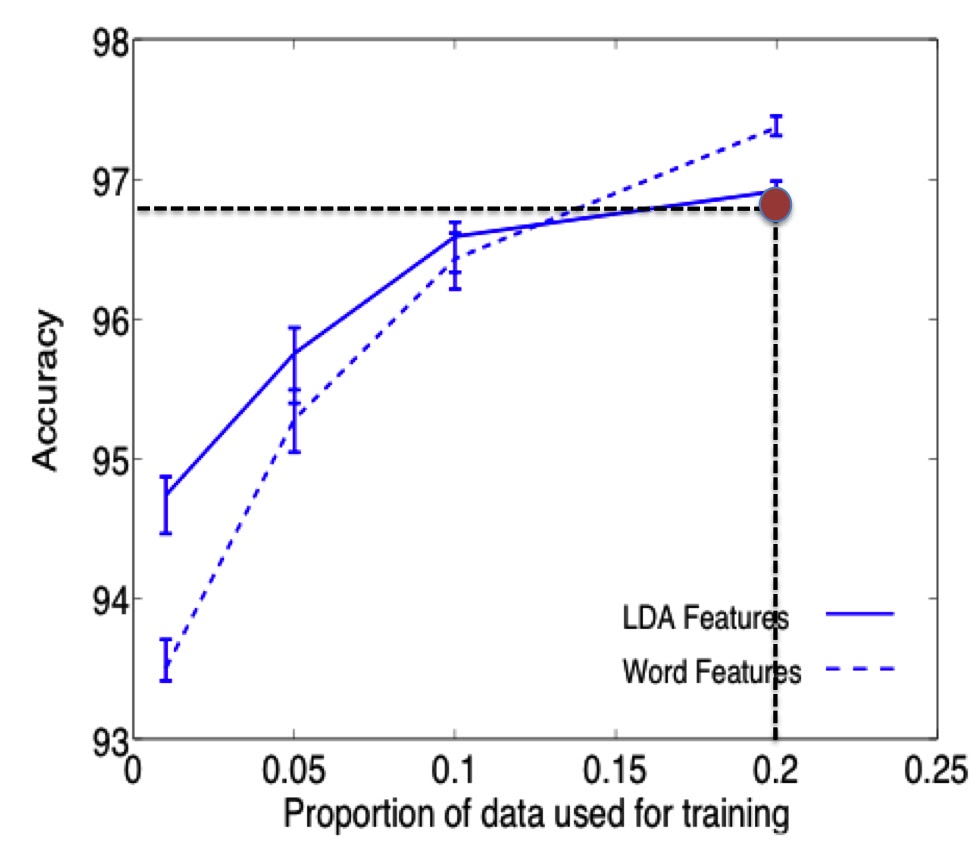 |
| Accuracy comparison: the red circle represents the accuracy obtained training an SVM with the features extracted through the Uncertainty Coefficients. |
I would like to remark that the features has been extracted using just the training set (20% of the data set), while the experiments done by the authors of the mentioned paper used the entire data set.
Better results can be easily achieved using the conditioned entropies in an iterative algorithm where the mutual information is measured respect a local set of features (adding the features that maximize the M.I. of the current set of features).
Our experiment shows clearly that the "Uncertainty Coefficients" criteria is a really good approach!
Soon, we will see how to use this criteria to build a clustering algorithm.
As usual: stay tuned.
cristian
Here is a web-based app that uses mutual information for feature selection http://www.simafore.com/blog/?Tag=keyconnect
ReplyDeleteThanks a lot for the info!
ReplyDeleteActually I'm not surprise that there are app for the features selection entropy based because it is a method very general purpose and easy to implement.
As you know I encourage always people in implementing by your own the algorithm, because it's the best way to understand advantages and limits of it and to adapt it to your specific problem (in this case there are many variants).
cheers
c.
Hi Christian,
ReplyDeleteI went through your note and I have several questions.
The weights you used are I(L,X) / H(X) of feature X ?
You write "from the above training set I extracted (after stemming and filtering process) all the words and I used them to build the boolean vectors."
Does that mean that you haven't counted the frequency of the words in the docs but used only its inclusion or non-inclusion?
Why haven't you search for the best C of SVM?
What do you mean exactly by "The above graph shows the entropy of the first 3000 features sorted by TF-DF score." ? TF-IDF makes sense only if we think documents+feature domain but not features domain only so I cannot imagine what do you exactly use for sorting. I must be misunderstanding something here.
This is not clear for me what you measured on accuracy in case of LDA since it is an unsupervised method. Can you explain it a bit.
Hi Lev,
ReplyDeleteexactly, for this experiment I ranked the features using this formulation.
The vectors have been built using the first 3000 features scored through TF-DF and sorted in decrescent order (by score).
The feature selection has been done over these vectors.
I didn't play a lot with C or kernel params just because I wanted highlight that feature selection plays a primary role respect param optimization. (of course, if you train with wrong param the classifier doesn't work well :) ).
The graph you mentioned has been built as following:
I sorted the features by TFDF score, then for each feature I plotted the respective entropy.
In this case there is a clear correlation between features having high TFDF score and High entropy: BUT THIS IS A TOY PROBLEM!! in the real scenario this correlation is much more smoothed.
About the accuracy:
LDA as clustering algorithm is by its nature unsupervised, but you can use it to extract features from the corpus.
In the paper I used for the comparison test, the authors built the vectors using the features extracted through LDA, then they trained an SVM and they measured the accuracy as True positive (being a boolean case it's not so wrong).
Of course I did the same to compare using the same metric.
Actually it should be better measure the sensitivity in this case because the two classes are not balanced in term of size.
Please let me know If I answered all your questions!
I hope to see you again, maybe as a follower clicking "join this site" on the right panel.
cheers
cristian
Please can you answer me : PCA or LDA reduce number of coefficents or number of frame for feature vector in speech recgnition?
ReplyDelete