The project has the aim to gather, provide and represent the knowledge in a different way.
For the time being I don't want to disclose too much info, but the main idea is to leverage my concept of the graph entropy to capture information in a document (or in a data set) to create a new kind of indexer.
One of the output of the algorithm is the generation of the mind map.
Experiment
Through the API provided by Twitter I downloaded the last 200 tweets from the hashtag #textanalytics.
I processed the tweets and here is the results:
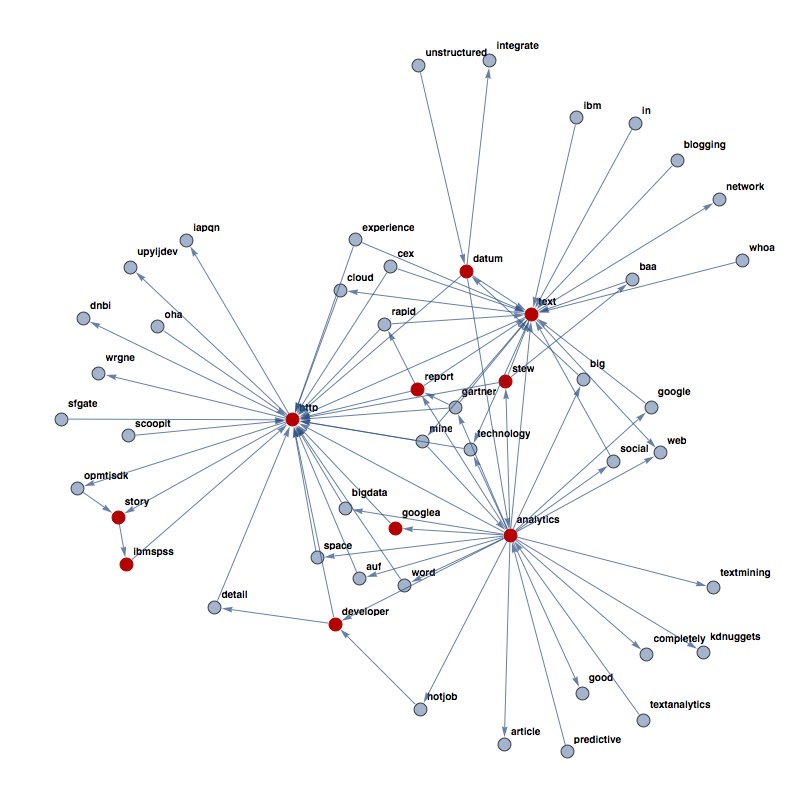 |
| #textanalytics mind map |
In red have been depicted the first 10 relevant words extracted through the graph entropy criteria.
It's interesting notice how the map shows intuitively the links among the words.
Of course the map can be enriched with more links or more relevant words: the choice depends on the user choice.
In the next posts I'll show you how the clustering techniques discussed in the former posts can be profitably used to create homogeneous group of words related each others.
what do you think?
Stay tuned
cristian