I mentioned that PCA works well under the condition that the data set has homogenous density.
Are we in this scenario?
I analyzed our data set to verify how the points are distributed; to do that I used the first three components suggested by PCA for the classes having TOPICS = "GOLD" and "GRAIN".
To highlight better the density I soiled the 3D coordinates with a weak gaussian noise just to avoid the presence of coincident points. Here you are the results:
 |
| In green "GRAIN" class, in violet "GOLD" class. Both soiled with weak gaussian noise. |
A countercheck of this quantitative analysis is provided by the second feature reduction algorithm we are testing: C 5.
A C 5 decision tree is constructed using GainRatio. GainRatio is a measure incorporating entropy. Entropy measures how unordered the data set is. Further details about C.5 are available at Quinlan's website: http://www.rulequest.com.
An Extremely interesting book about Entropy application is the famous "Cover - Thomas":
Elements of Information Theory, 2nd Edition
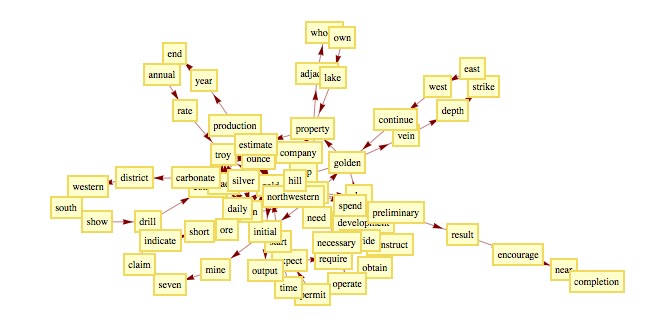
Let's show the output of C 5 using the default setting:
The above Tree represents the Decision paths for a data set composed by the Three classes having TOPICS = "GOLD","GRAIN","OIL".
To build the vector I used the TF DF feature set of the class "GOLD".
(in the next post I gonna explain why I'm building vectors of class X using feature set of the class Y :) ).
As you can see in the graph , only few features have been used:

 |
| The Decision Tree returned by C 5 The leaves (depicted with red triangles) represent the class assigned by the algo for this decision path. A = "GOLD", B= "GRAIN", C= "OIL". The left members of the node inequalities represent the feature number. |
To build the vector I used the TF DF feature set of the class "GOLD".
(in the next post I gonna explain why I'm building vectors of class X using feature set of the class Y :) ).
As you can see in the graph , only few features have been used:
Notice that C 5 returns different features respect PCA algo! Moreover it suggests us to use only 7 features: it is an amazing complexity reduction!!
I used C 5 just to analyze the important features, but C 5 is itself a classifier! In the below image the classification accuracy for the mentioned classes.

I used C 5 just to analyze the important features, but C 5 is itself a classifier! In the below image the classification accuracy for the mentioned classes.
Is it a good result? Apparently yes, but ...if you have a look to the class "GRAIN" (B) the results are not so brilliant!!.
Don't worry we will see how to improve dramatically these accuracy.
At this point we have discussed about many algorithms, techniques and data set.
So where we are, and where we gonna go?
 |
| Auto classification Road Map |
cristian