A statistical discrete distribution (based on geometric random variable) to depict a document. In the post it's presented a probabilistic density function to describe a document thru the underlying stochastic process.
 |
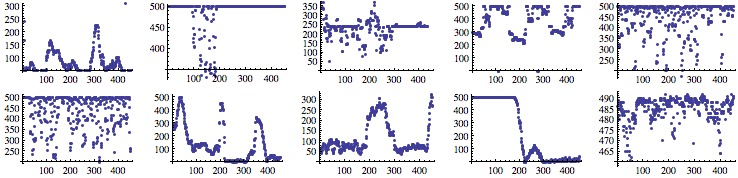
PDF-CDF charts and PDF analytical formula for document of length Z.
Results for a document of two words.
|
We often discussed about the importance of the features extraction step in order to represent a document.
So far, I mostly presented techniques based on "bag of words" and some more sophisticated approach to capture the relation among such features (the graph entropy, mutual information, and so on).
In the last weeks I started to think about a different perspective in order to capture the essence of a document.
The idea
What is a document from statistical point of view?
I tried to give an answer, and I came to the following (expected) conclusion:
- A document is a stochastic process of random variables - the words of the document.
- In a document as in a whatever statistic process, the occurrences of the random variables and functions over them doesn't provide complete description of the process.
- The joint distribution of the waiting times between two occurrences of the same variable (word) encloses all the significative links among the words.
This formalization allows us to think to a document as a statistic distribution characterized by its own density and cumulate function.
The waiting time is very well depicted by geometric distribution.
The waiting time is very well depicted by geometric distribution.
Formalization
A document is a process of geometrically distributed random variables:



I think it's more worthwhile to show how the solution comes!
Exponents:
Let's put the q_a and q_b exponents properly sorted on a matrix:
Is it easier now find the "low" to build the above matrix?
|
where each random variable is described as follow:
Let's consider the following document composed by a sequence of two words: "a" and "b".
The Problem
- What is the probability function associated to a document Dk?
The Probability of Dk is given by:
The below image should explain better what I meant:
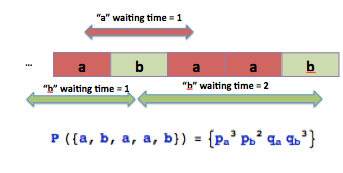 |
| Probability of Document Dk q = 1-p |
Probability Density Function
-> From now, if not clearly specified I will refer to a document of two words (as above described).
Questions:
- What is the analytical representation of the above function?
- Is it the above function a probability function?
1. Analytical formulation
This is the funny part: I like combinatoric... the art of tally!
To solve the problem, I'm sure, there are several strategies, I used just the way that is more aligned to my mind setting: I put all the options on the table and I start to check to gather them together according to some criteria :)
- The formulation of the "p" is a joke: the sum of the exponents must be equal to the size of the vector.
- the formulation for the "q" requires some deeper thinking.
I think it's more worthwhile to show how the solution comes!
Exponents:
Let's put the q_a and q_b exponents properly sorted on a matrix:
 |
| The split over the anti-diagonal makes the calculus easier. |
Coefficients:
The same configuration of exponents can be related to different configurations of the words in the document:
 |
| The different configurations (20) of two words in a document having length = 8. |
Let's put the the occurrences of the different configurations of words for the same exponents configuration in a matrix:
 | |
|
... If you don't like play around with combinatorics, you can ask help to The On-Line Encyclopedia of Integer Sequences®!
Ok, ok you are too lazy...: the solution is Binomial[k+i,k].
The Analytical formula
The above matrixes suggest that the analytical formula is composed by two main addends: one for the orange side and another one for the green side.
For a document of two words the Probability Density Function is the following:
I don't want enter in theoretical details to proof that the above formula is probability function (after all this is a blog by practical means!).
The only point I want to remark is that the convergence to a PDF is guaranteed for a length of document that tends to Infinity.
The above formula can be further reduced and simplified (in the easy case of 2 words) if you consider the following conditions:
In the CDF, we sum the probability contribute of all documents composed by two words having length =1, 2, ..., Infinity.
As you can see, the contribute of documents having length >50 is negligible for whatever value of pa.
These kind of distributions based on geometric variables are often used in maintenance and reliability problems, so I encourage you to have some reading on that!
Next Steps
In the next posts I'm going to explain
I did the above exercise just for fun, with out any pretension to have discovered something new and or original: if you have some paper/book/reference about identical or similar work, please don't hesitate to contact me!
Don't rush, stay tuned
cristian
For a document of two words the Probability Density Function is the following:
| PDF for a document composed by two words. qa = 1-pa = pb; pa+pb = 1. |
The only point I want to remark is that the convergence to a PDF is guaranteed for a length of document that tends to Infinity.
The above formula can be further reduced and simplified (in the easy case of 2 words) if you consider the following conditions:
qa = 1-pa = pb => qb=pa (pa+pb = 1).
Basically in the above case the PDF is function of 1 variable. |
| PDF and CDF for a document of 2 words. |
As you can see, the contribute of documents having length >50 is negligible for whatever value of pa.
These kind of distributions based on geometric variables are often used in maintenance and reliability problems, so I encourage you to have some reading on that!
Next Steps
In the next posts I'm going to explain
- some properties of the function
- its extension to multiple variables
- entropy
- practical applications
I did the above exercise just for fun, with out any pretension to have discovered something new and or original: if you have some paper/book/reference about identical or similar work, please don't hesitate to contact me!
Don't rush, stay tuned
cristian