We have also seen that to obtain a good approximation of the function, long training session is required; the reason of this inefficiency lays in one and on the gradient surface and in another hand on the strategy adopted to train the system.
Let me spend few words about the gradient surface:
The gradient surface conformation is strictly related with the number of monomials used to approximate functions, so
- if you use fews monomials the approximation cannot be good because you are using less complexity respect the complexity of the original function and the gradient will have pretty regular convex surface with bottom equal to best approximation achievable by the linear combination of monomials chosen.
- if you use too many monomials, you are building a complex gradient function (because the number of its parameters are growing), so you increase the risk to fall down in a local minimum.
I mentioned that annealing strategy can help to overcome the barriers imposed by local minimums, but for the time being I prefer show you a little bit more sophisticated strategy: the clustering learning.
As you know usually the clustering techniques are used to divide data in different categories, but I would like once again deliver the message that in data mining (and in text mining as well) what is real important is not the product, the tool or the suite, but the knowledge, the creativity and the skills to abstract the problems and the algorithms and adapt the second one to solve the first one.
Divide et Impera (Latin motto)
... that is divide the problem in sub problems, find sub solutions and merge them to obtain the overall solution.
The strategy is very easy to describe:
1. Divide the domain of your function in k sub intervals.
2. Initialize k monomials;
3. Consider the monomials as centroids of your clustering algorithm.
4. Assign the points of the function to each monomial in compliance to the cluster algo.
5. Use the gradient descent to adjust the parameters of each monomial.
6. Go to 4. until the accuracy is good enough.
Basically in the former version we had this approximation:
 |
| Function Approximation through power real polynomials |
While in this approach we introduce the membership of function which assign each point to each cluster (in this case monomial)
 |
| Power Real Polynomials approximation with clustering approach |
Let's see the result obtained with the sinusoid function (please compare with the former results obtained with the canonical gradient descent).
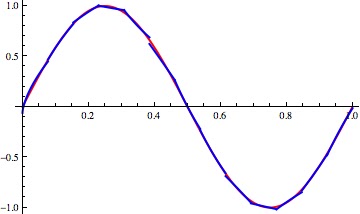 |
| Clustering approach to fit the Sin(x) function |
First Example

 |
| The spheres represent the points belonging to the original function, while the planes are representing the monomials surface found by clustering & gradient. (approximation with 36 monomials) |
 |
| Original Function depicted with blue points; Fitting depicted with Orange Points |
Second Example
The function chosen is the following:

The fitting obtained applying the above monomials and the membership function:
The function chosen is the following:
 |
| On the left side the original function, on the right side the hyperplanes (monomials) found by gradient descent cluster based. |
 |
| The graphs shows the plane described by the original function. In blue the points belonging to the original function. In orange the fitting obtained using the clustering based procedure. |
As usual: Stay Tuned
Cristian
thanks
ReplyDeleteGreat thoughts you got there, believe I may possibly try just some of it throughout my daily life.
ReplyDeleteFunction Point Estimation Training
ReplyDeleteThanks for sharing, check out
Data Mining Service Providers
Data Mining Process