Let's start the treasure hunt!
1. Don't always trust your data: often they are not homogeneous.
In the post I put in relation the quakes in the range time between [~1800,1999] with the respective sunspots distribution.
Consider our example: the right question before further analysis should be: "had the quakes magnitude been measured with the same kind of technology along the time?"
I would assume that is dramatically false, but how can check if our data have been produced in a different way along the time?
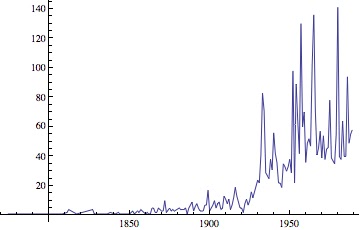
In this case I thought that in the past, the technology wasn't enough accurate to measure feeble quakes, so I gathered the quakes by year and by the smallest magnitude: as you can see, it is crystal clear that the data collected before 1965 have been registered in different way respect the next period.
 |
| The picture highlights that just major quakes (with magnitude > 6.5) have been registered before 1965. This is the reason of the outward increasing of quakes! |
In this case the best way to clean up the dataset is to filter just quakes having magnitude grater than 6.5.
Let me show you a different way to display the filtered data: "the bubble chart".
 |
| The size of the bubble is representative of the magnitude of the quakes |
 |
| The size of the bubble is representative of the number of the quakes |
I love the bubble chart because it is really a nice way to plot 3D data in 2D!!
2. Sampling the data: are you sampling correctly your data?
In the former post I considered only the quakes registered in USA.
Is it representative of the experiment we are doing?
The sunspots should have effects on the entire Earth's surface, so this phenomena should produce the same effects in every place.
...But as everybody knows: there are regions much more exposed to quakes respect other areas where the likelihood to have a quake is very low.
So the right way to put in relation the two phenomena is to consider the World distribution of the quakes.
3. Don't rely on the good results on Training Set.
This is maybe the worst joke I played in the post :) I showed you very good results obtained with the support regression model.
...Unfortunately I used the entire data set as training set, and I didn't check the model over a new data set!
This kind of mistake in the real scenario, often generates false expectation on your customer.
The trained model I proposed seemed very helpful to explain the data set, but as expected it is not able to predict well :(.
How can you avoid the overfitting problem? The solution of this problem is not so trivial, but in principle, I think that cross validations techniques are a safe way to mitigate such problem.
Here you are the new model:
 |
| The left graph shows the Training Set (in Blue the number of quakes per year, in Red the forecasting model). The graph on the right side shows the behavior of the forecasting model over a temporal range never seen before by the system. The mean error is +/-17 quakes per year. |
 |
| The Magnitude forecasting (on the left the training set, on the right side the behavior of the forecasting model over the test set). The mean error is around +/-1.5 degrees. |
Just to have a better feeling of how the regressor is good, I smoothed the data through a median filter:
 |
| Moving Median Filtering applied to the Magnitude regressor. |
Looking at the above graph, it seems that the regressor is able to follow the overall behavior.
As you can see such filtering returns a better understanding of the "goodness" of your models when the function is quite complex.
4. You found out a good regressor, so the phenomena has been explained: FALSE.
You could find whatever "link" between totally independent phenomena ... but this link is just a relation between input/output. nothing more, nothing less.
As you know this is not the place for theorems, but let me give you a sort of empirical rule:
"The dependency among variables is inverse proportional to the complexity of the regressor".
As usual stay tuned.
Cristian